10x: Service Discovery at Clay.io
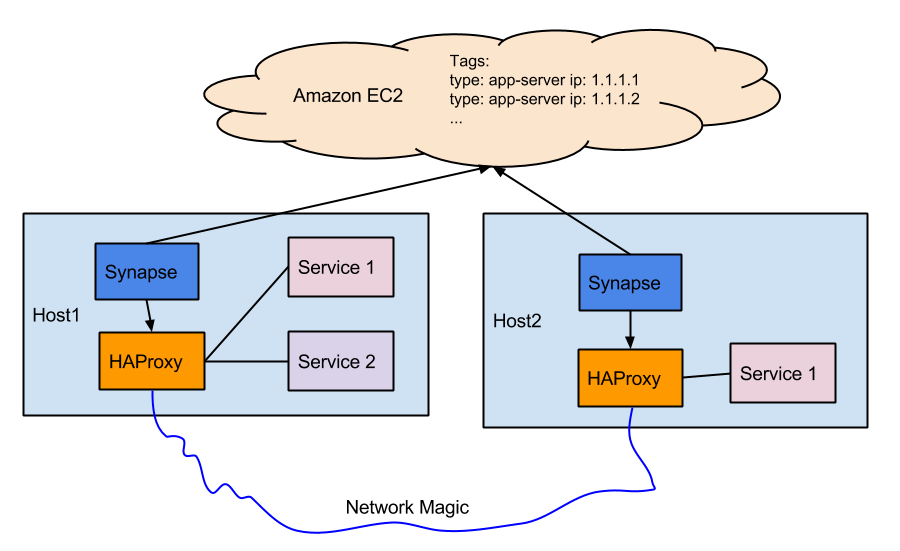
Architecture
Service Oriented Architectures can be one of the most iterable and available software configurations for building almost any product. There are many challenges that come with these systems, probably the biggest of which is service discovery. This is how your services will communicate with each other. For our service discovery, we turn again to Docker. If you haven't read how we do deploys: Docker at Clay.io
Tutorial
Synapse (https://github.com/claydotio/synapse) is a daemon which dynamically configures a local HAproxy configuration which routes
requests to services within your cluster. It watches Amazon EC2 (or another endpoint) for services, specified in a configuration file.
We use the ec2tag watcher, which easily lets us add servers to our cluster by tagging them.
HAProxy
Alright, so let's start with the services. They will be talking to each other via the local HAProxy instance. Because services run inside docker, we need to specify the host IP for services to look for services at a specific port.
Here, we use Ansible to pass the local IP and port to service running on that machine.
SERVICE_API=http://{ ansible_default_ipv4.address }:{ service_port }
For a service to use another service, they simply make calls to that IP/port.
The key here is that the IP is the local machine IP, which is handled by HAProxy.
We have released an HAProxy docker container which watches a mounted config file,
and updates automatically on changes:
https://github.com/claydotio/haproxy
docker run
--restart always
--name haproxy
-v /var/log:/var/log
-v /etc/haproxy:/etc/haproxy
-d
-p 50001:50001
-p 50002:50002
-p 50003:50003
-p 50004:50004
...
-p 1937:1937
-t clay/haproxy
By default, we use the noop config at /etc/haproxy, which gets mounted inside the docker container and watched for changes. We will be mounting the same haproxy config inside our synapse container in a moment. It's important to note that if this container goes down, all services on the machine will be cut off from all other services. For that reason, we have allocated additional ports to the container for use with new services in the future (as they cannot be dynamically allocated).
Synapse
Ok, now it's time to actually set up synapse.
Running synapse (thanks to our public Docker container) is easy.
docker run
--restart always
--name synapse
-v /var/log:/var/log
-v /etc/synapse:/etc/synapse
-v /etc/haproxy:/etc/haproxy
-e AWS_ACCESS_KEY_ID=XXX
-e AWS_SECRET_ACCESS_KEY=XXX
-e AWS_REGION=XXX
-d
-t clay/synapse
synapse -c /etc/synapse/synapse.conf.json
Notice how we are mounting a synapse config, and an haproxy config inside the container. The HAProxy config is our noop config from before (because it will be auto-generated by synapse), but let's look into configuring synapse.
Configuring synapse can be a bit tricky, as the documentation could be better. Here is an example config that should explain everything that's missing in the docs:
{
"services": {
"myservice": {
"discovery": {
// use amazon ec2 tags
"method": "ec2tag",
"tag_name": "servicename",
"tag_value": "true",
// if this is too low, Amazon will rate-limit and block requests
"check_interval": 120.0
},
"haproxy": {
// This is the port other services will use to talk to this service
// e.g. http://10.0.1.10:50003
"port": 50003,
"listen": [
"mode http"
],
// This is the port that the service exposes itself
"server_port_override": "50001",
// This is our custom (non-documented) config for our backup server
// See http://zolmeister.com/2014/12/10x-docker-at-clay-io.html
// for details on how our zero-downtime deploys work
"server_backup_port": "50002",
"server_options": "check"
}
}
},
// See the manual for details on parameters:
// http://cbonte.github.io/haproxy-dconv/configuration-1.5.html
"haproxy": {
// This is never used because HAProxy runs in a separate container
// Reloads happen automatically via the file-watcher
"reload_command": "echo noop",
"config_file_path": "/etc/haproxy/haproxy.cfg",
"socket_file_path": "/var/haproxy/stats.sock",
"do_writes": true,
"do_reloads": true,
"do_socket": false,
// By default, this is localhost, however because HAProxy is running
// inside of a container, we need to expose it to the host machine
"bind_address": "0.0.0.0",
"global": [
"daemon",
"user haproxy",
"group haproxy",
"chroot /var/lib/haproxy",
"maxconn 4096",
"log 127.0.0.1 local0",
"log 127.0.0.1 local1 notice"
],
"defaults": [
"log global",
"mode http",
"maxconn 2000",
"retries 3",
"timeout connect 5s",
"timeout client 1m",
"timeout server 1m",
"option redispatch",
"balance roundrobin",
"default-server inter 2s rise 3 fall 2",
"option dontlognull",
"option dontlog-normal"
],
"extra_sections": {
"listen stats :1937": [
"stats enable",
"stats uri /",
"stats realm Haproxy Statistics"
]
}
}
}
Conclusion
That's all there is to it. Special thanks to Airbnb for open-sourcing their tool,
which allowed us to set up service discovery in a simple and scalable way. For those
not on Amazon EC2, there is a Zookeeper watcher (which we did not want to deal with),
and hopefully soon an etcd watcher:
https://github.com/airbnb/synapse/pull/58
Once that's merged, we may move to using Nerve with etcd instead of EC2 tags to handle service announcement. For reference, I'll leave this etcd example docker information here:
curl https://discovery.etcd.io/new?size=3
docker run
--restart always
--name etcd
-d
-p 2379:2379
-p 2380:2380
-v /opt/etcd:/opt/etcd
-v /var/log:/var/log
-v /etc/ssl/certs:/etc/ssl/certs
quay.io/coreos/etcd:v2.0.0
-data-dir /opt/etcd
-name etcd-unique-name
-listen-client-urls http://0.0.0.0:2379
-listen-peer-urls http://0.0.0.0:2380
-advertise-client-urls http://localhost:2379
-initial-advertise-peer-urls http://localhost:2380
-discovery https://discovery.etcd.io/XXXXXXXXXXXX
-initial-cluster-token cluster-token-here
(see discovery docs for url)